Merhaba, bugün SQL Server’de oluşturduğumuz sorgularımızın ne kadar bir sayfa okuması sonucunda geldiğini ve bu sorguya ait gelen verilerin ne kadar sürede geldiği konularına değineceğim. Sorgularımızın index yapılarını ve bu indexlerin bozulma gibi durumlarında neler yapabileceğimizi, bunları nasıl planlı hale getirip daha hızlı sonuçlar alabileceğimize bakacağız. Hadi başlayalım..
İlk olarak örnek CRM database backup’unu buradan indirebilirsiniz. Devamında ise Customers tablosu altında örnek bir ad soyad sorgusu için şu şekilde bir sorgu yazıyoruz.
SET STATISTICS IO ON
SELECT * FROM Customers where NAMESURNAME like 'Muhammed Ali ÇATALDAŞ'
Burada set statistics io on bize sorgumuzun ne kadarlık okuma sonucunda getirdiği hakkında bilgi vermektedir. Bu sorgu sonucunda messages kısmına tıkladığımızda şu şekilde bir sonuç gelmektedir.

Bu sonucun ardından sorgunun 38134 lik bir okuma sonucunda geldiğini ve şuan benim cihazım üzerinde yavaş gelmemiş olsada yüksek boyutta bir okuma gerçekleştirdiğini görmekteyiz. Bu işlemi index yapılarıyla nasıl daha okunabilir hale getireceğimizle devam edelim…
Clustered Index ve NonClustured Index
Clustered index identity ve primary key alanlarımıza verebileceğimiz index türüdür. Her tablo için bir adet verilmekte olup, nonclustered index ise daha fazla verilebilmektedir.
Customers tablomuz için ilk olarak bir clustered index oluşturalım ve buradan Add kısmından ID alanını ekleyelim.
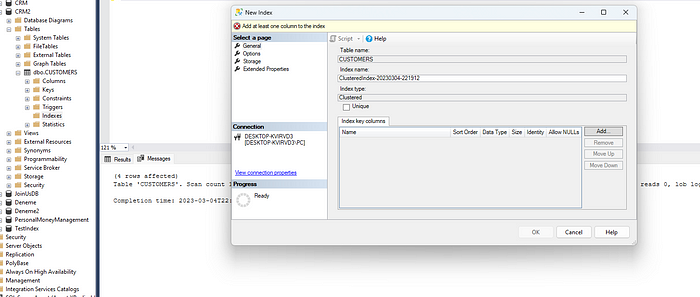
Diğer bir adımda ise nonclustered index oluşturacağız ve burada NAMESURNAME kolonunu seçiyor olacağız.
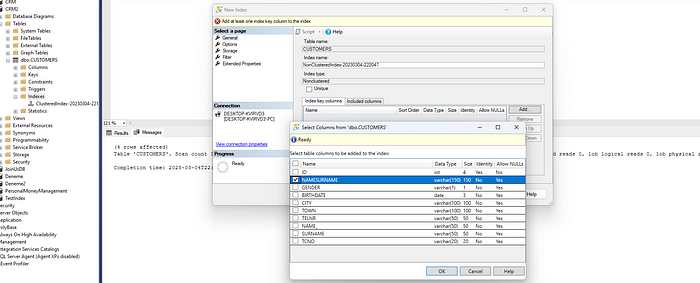
Bu indexlemeler oluşturulduktan sonra tekrardan SQL sorgumuzu çalıştırıyoruz.
SET STATISTICS IO ON
SELECT * FROM Customers where NAMESURNAME like 'Muhammed Ali ÇATALDAŞ'
Çıkan sonuçta yine messages kısmına tıklayıp ne kadarlık bir okuma gerçekleştirdiğini kontrol edelim.

Burada da görüldüğü üzere indexlemeler yapıldıktan sonra sayfa okumanın ve sorgunun ne kadar hızlanabileceğini görmüş olduk. Bu sorgunun execution planına bakarak bir yorumlama gerçekleştirecek olursak şu şekilde bir yorumda yapabiliriz.
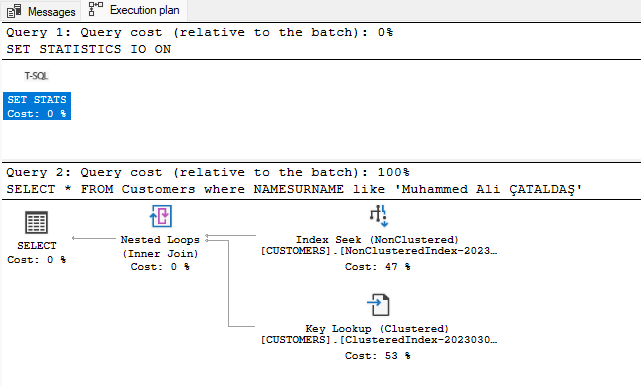
Plandan çıkan sonuca göre 47 lik bir oranda Index Seek yaparken 53 lük bir oranda key lookup yaparak clustered index’te oluşturduğumuz Id alanına giderek kopya üzerinden tekrar bir okuma gerçekleştirmektedir. Burada kullanım amacınıza göre şekil alabilmektedir. Bu durumu şöyle açıklamak istiyorum;
Nonclustered index’inizde includede columns içinde tüm alanlarınızı seçip ekleme yaparsanız sorgunuzdakı key lookup’un ortadan kalktığınızı göreceksiniz fakat bunun yerine kullandığınız columnlarınıza ait ayrı ayrı nonclustered index oluşturmanız önerilmektedir. Eğer included columns’un içinden bir ekleme yaparsanız index_size nizde bir boyut artışı olacaktır. Bunu kontrol etmek için aşağıdaki sorguyu çalıştırıp sonucu görebilirsiniz.
SP_SPACEUSED Customers
Included Öncesi Index Size

Included Sonrası Index Size

Included sonrası execution plan sonucunda index seek 100% olup key lookup ortadan kalkmıştır.
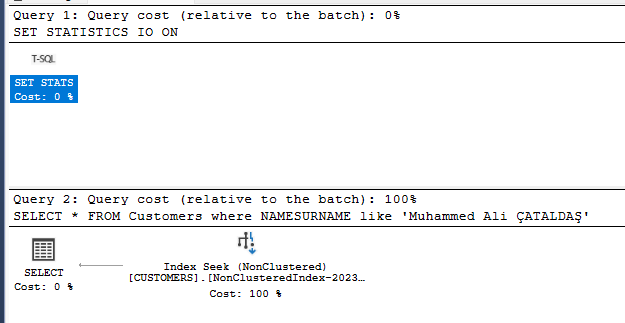
Index Bozulmaları & Fragmentation ve Fill Factor Kavramları
Index bozulmaları tablolara veri akışı sürekli olduğu için ortaya çıkması çok normal olan bir durumdur. Bu gibi durumlarda indexlerimizin fragmentation’larınını kontrol etmemiz gerekmektedir. Şimdi customers tablomuzdaki oluşturduğumuz nonclustered index’in fragmentation’unu kontrol edelim. Bunun için index’imize çift tıklayıp aşağıdaki ekranı açalım.
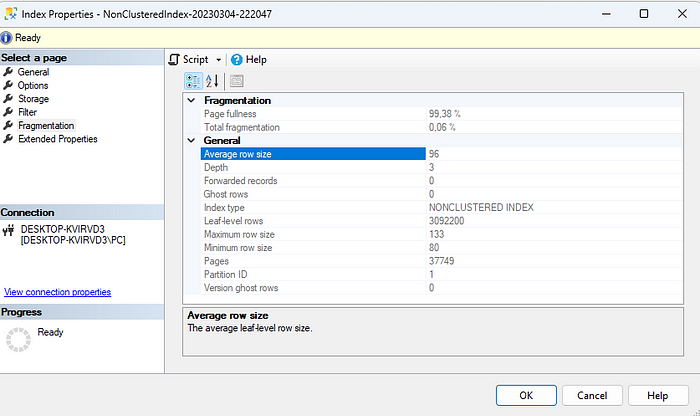
Resimde görüldüğü üzere Page fullness 99.38 ve total fragmentation oranı ise 0.06'dır. Buradan index’imizin gayet sağlıklı olduğu sonucu ortaya çıkmaktadır. Şimdi bu tablomuzdaki indexi bozmaya yönelik yeni veri girişi sağlayalım. Bunun için direkt şu sorguyu çalıştırabilirsiniz.
INSERT INTO CUSTOMERS
(NAMESURNAME, GENDER, BIRTHDATE, CITY, TOWN, TELNR, NAME_, SURNAME, TCNO)
SELECT TOP 400000
NAMESURNAME, GENDER, BIRTHDATE, CITY, TOWN, TELNR, NAME_, SURNAME, TCNO
FROM CUSTOMERS
Bu sorguyu çalıştırdıktan sonra nonclustered index’imize ait fragmentationu tekrar kontrol ettiğimizde şöyle bir sonuç ortaya çıkmaktadır.
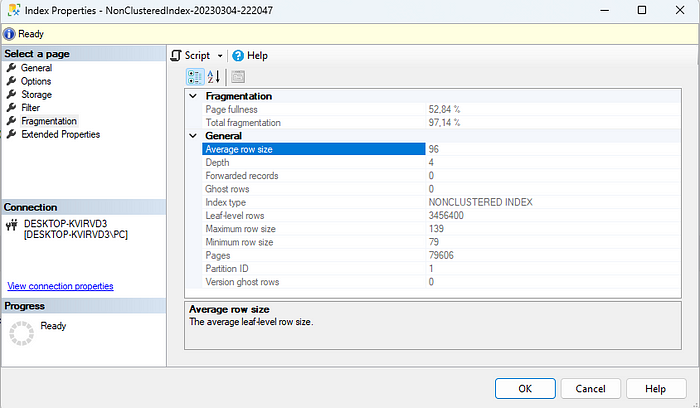
Bu sonuca baktığımızda ise index’imizin bozulduğunu çok net bir şekilde görebiliyoruz. Bu gibi durumlarda index’imizi rebuild edip düzeltme sağlayabiliriz fakat bu işlemi yaparken eğer SQL Server’iniz enterprise sürümü değilse kitleniyor olup içeriye veri girişi engellenmiş olacaktır. Bu gibi durumlar için maintenance planları uygulanıp bunları SQL Server’inizin az kullandığı saat dilimlerinde planlayıp çalıştırarak çözebiliriz. Buna rağmen yinede çok yoğun bir çalışma durumu var ve sürekli veri girişi var ise Fill Factor kavramından bahsetmek istiyorum.
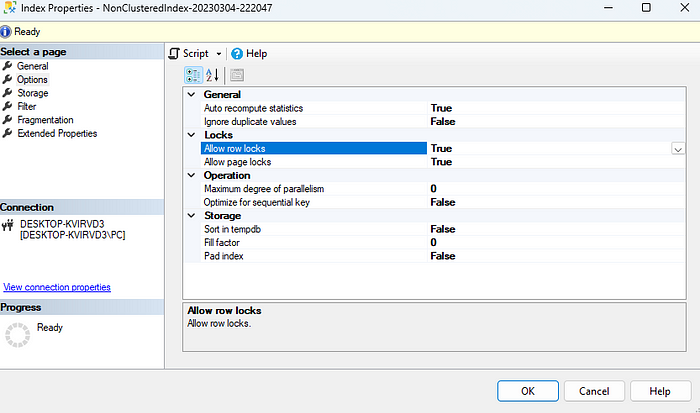
Resimde görüldüğü gibi Nonclustered Index’lerimizde Options alanına tıklayıp gittiğimizde fill factor’un 0 olduğunuzu göreceksiniz. Fill factor sayfamızın belli bir alanına kadar dolu tutup boşluk bırakma işlemi için kullanılmaktadır. Örnek veriyorum siz bu alana 80 girerseniz sayfanız %80 lik bir doluluk kabul edip üzerine ekleme yapmayacaktır. Bu şekilde index leriniz bozulana kadar vakit kazanmış olacaksınız. Bu işlemi yaparken veri boyutunuzun büyüyeceğini unutmamalısınız. Fill Factor için genelde 80 ve 90 oranları best practice olarak kabul edilmektedir.
Maintenance Planı
SQL Server’inizde maintenance bir plan oluşturup index bozulmalarını düzenli bir şekilde düzeltme işleminden bahsedelim. Bunun için ilk olarak SQL Server Agent’iniz pasif durumdaysa lütfen aktif duruma getirelim. Devamında ise management’e tıklayarak açılan menüden toolbox alanına gidiyoruz. Rebuild index task’ı sürükleyip bırakarak planın içine dahil ediyoruz. Task’ın için oluşturmadan önce çalışma sürelerini schedule alanından belirliyoruz.
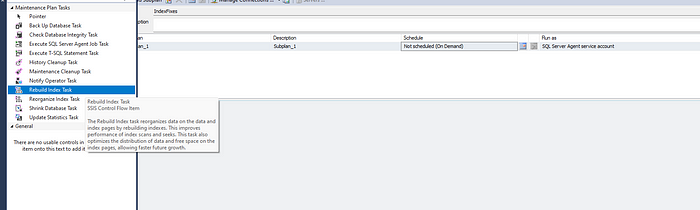
Devamında ise sürüklediğimiz task’e tıkladığımızda database seçimini yaparak planımızı aşağıdaki gibi oluşturuyoruz.
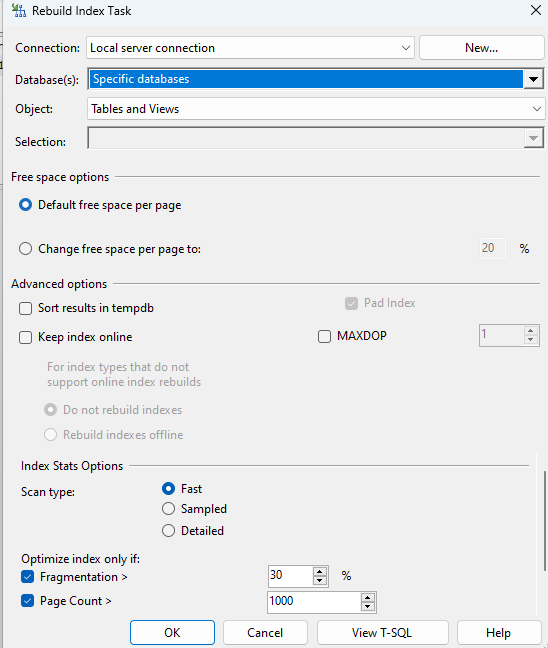
Sonuç olarak baştan özetleyecek olursak clustered index, non clustered index, fragmentation, fill factor ve maintenance planlarına amacımız doğrultusunda değinmiş olduk. Bunların derinleme araştırmasını yapabilirsiniz. Herkese bol şans…